In one of my blog posts Perform Storage Maintenance on NetApp Clustered Data ONTAP with ZERO downtime, I have shared about performing non-disruptive Storage maintenance using Storage Failover feature with NetApp Clustered Data ONTAP. In this blog post I will cover scenarios where the following maintenance has to be performed?
- Perform upgrade on the disk shelves.
- Perform maintenance on the disk shelves for e.g. replacing the disk drives or updating the firmware.
Assuming that you have to perform the above maintenance tasks during business hours and you have a VMware View Linked Clone pool provisioned, how would you deal with this?
Though the task is complex but the solution is easy with Volume Move feature in NetApp Clustered Data ONTAP.
To demonstrate this, I have setup a lab with 125 View Desktops provisioned NFS volume “nfs3_1tb_aggr01”which is located on the disk shelf attached to one of the FAS3240 nodes. I have two FAS 3240 nodes configured in HA pair.
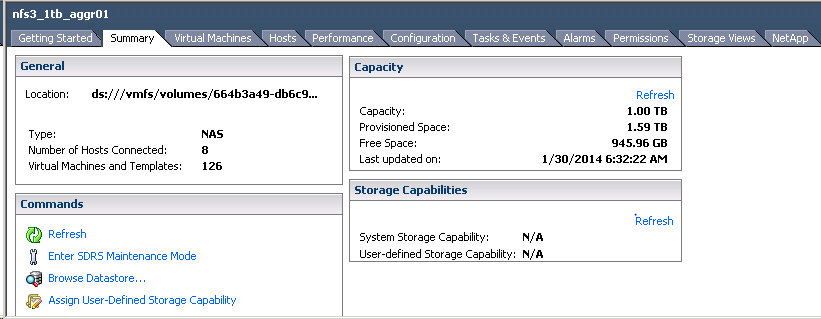
Assuming that you have to perform some offline maintenance tasks on the underlying aggregate or disk shelf where “nfs3_1tb_aggr01” resides. How would you deal with this situation? especially when the business cannot afford downtime.
As a Storage or VMware View Administrator you have the following options to relocate the 125 View Desktops from aggr01 to another aggregate on another disk shelf which is connected to the HA pair:
Request the View Desktop users to log off AND Rebalance by VMware View – In this option you would have to take into account the down time required to complete the Rebalance task. NOTE: VMware View Rebalance would not log off all users at once, it would do that in a batch of 12 View Desktops.
Non-Disruptively relocate the VMs from aggreagate01 to aggregate02 using Volume Move by NetApp Clustered Data ONTAP.
To avoid any downtime, I chose Volume Move to migrate the View Desktops to a different aggregate on another disk shelf.
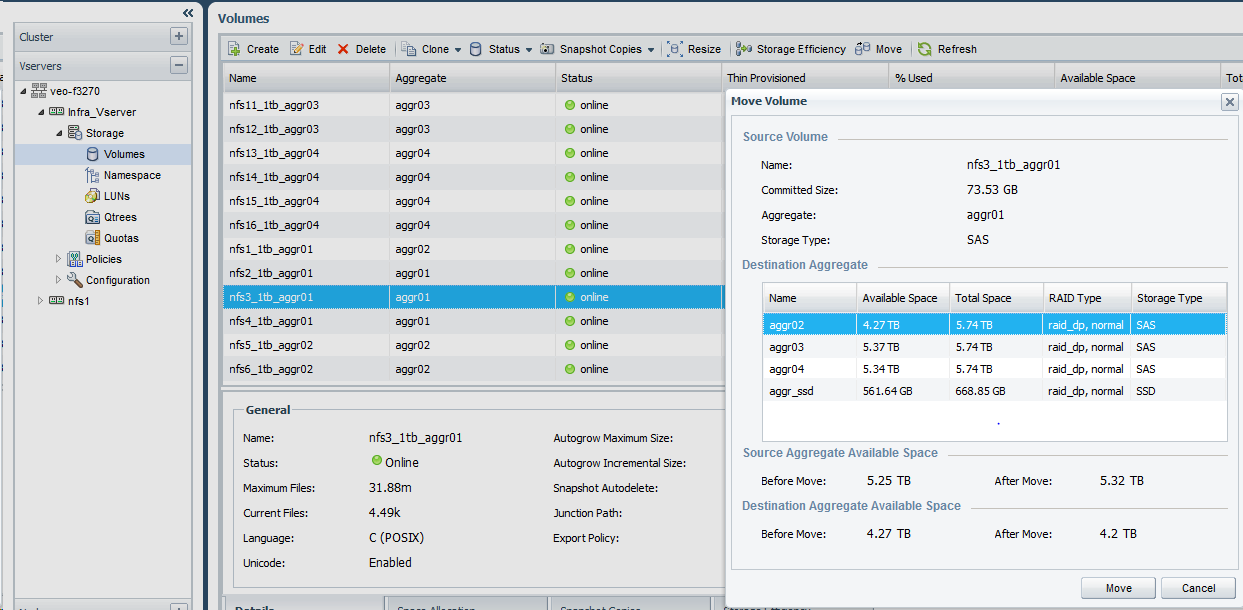
The process to move a volume is simple to perform. If you are connected to the NetApp OnCommand System Manager, select the Volume > click Move > chose the Destination Aggregate.
Alternatively, you may also use ONTAP CLI to perform Volume Move
# volume move start -vserver Infra_Vserver -volume nfs3_1tb_aggr01 -destination-aggregate aggr02 -cutover-window 45
You may also check the statistics of the volume move task using the following command.
lab-f3270::> volume move show -vserver Infra_Vserver -volume nfs3_1tb_aggr01
Vserver Name: Infra_Vserver
Volume Name: nfs3_1tb_aggr01
Actual Completion Time: Wed Jan 29 13:26:49 2014
Specified Action For Cutover: defer_on_failure
Specified Cutover Attempts: 3
Specified Cutover Time Window: 45
Time User Triggered Cutover: -
Time Move Job Last Entered Cutover: Wed Jan 29 13:26:15 2014
Destination Aggregate: aggr02
Detailed Status: Successful
Estimated Time of Completion: -
Managing Node: veo-filer1
Percentage Complete: 100%
Move Phase: completed
Estimated Remaining Duration: -
Replication Throughput: 196.0MB/s
Duration of Move: 00:07:21.000
Source Aggregate: aggr01
Start Time of Move: Wed Jan 29 13:19:28 2014
Move State: done
IMPORTANT:
Consider the following points before attempting volume move to ensure successful completion.
- Committed Size – The amount of data that needs to be copied.
- Incoming I/O Rate – The amount of active I/O during the volume move process.
- Throughput – The data transfer is done on the cluster network. The throughput would depend on the bandwidth available on this network.
For detailed information and best practices about Volume Move, please refer to TR 4074 - DataMotion for Volumes Best Practices and Optimization System Operating in Cluster-Mode.